SharePoint Syntex is the AI-powered ability for Microsoft 365 to learn and understand your documents, enabling knowledge to be extracted and automated processes to be implemented around your content. Building on earlier work I did, I've worked on a couple of Syntex implementations recently, one for a client and one internal to us at Content+Cloud. Putting Syntex into action in the real world is quite different to general experimentation, and in this post I want to share some learnings as I've worked with different scenarios. Before that, if you're looking for some fundamentals content on Syntex some of my earlier articles might be useful:
Syntex is an evolving technology and although Microsoft have worked hard to democratise the AI and put it in the hands of non-developers, there's definitely a learning curve and the constructs used in the training of AI models take some time and experience to get the most from. It starts with making the right choice between Syntex' two approaches (as discussed in
choosing between structured and unstructured document understanding) and then requires a good understanding of the constructs and some trial and error (including interpreting the feedback received) during the AI training process.
Background - real world scenarios these tips are based on
Before I go into the tips I think it's useful to understand the types of documents I trained Syntex to understand. The first is known as a 'method statement' and is used in construction and engineering in the UK - it's required by law in some scenarios but is also commonly used on practically any service task where risk has been identified. Examples I've seen include replacing a building's alarm system or even cleaning windows with a tall ladder. The method statement goes alongside a risk assessment, and the overall process is often known as RAMS (Risk Assessment - Method Statement). The method statement describes the 'safe system of work', detailing the control measures taken for the identified hazards and risks. Here are the first pages from a couple of examples - as you can see the formats are quite different, but that's OK for Syntex:
For these types of document, Syntex document understanding works best.
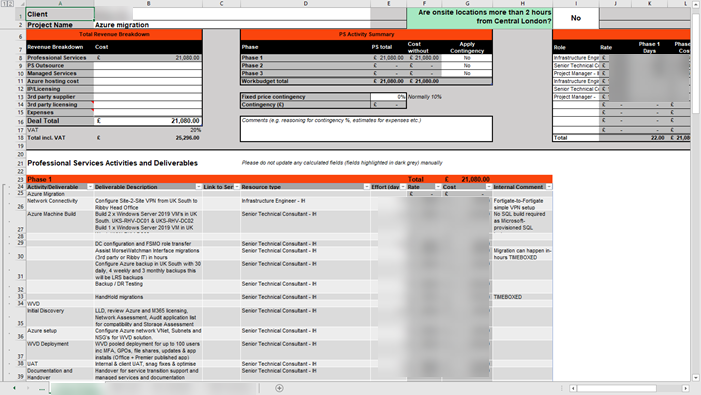
The other work I'm doing revolves around an Excel format we use commonly at
Content+Cloud which looks like this:
As you can see this one is very tabular in nature, and unsurprisingly if you know Syntex I found that the unstructured document processing model works best here.
My top 5 Syntex tips
1. To extract from Excel, convert to PDF first
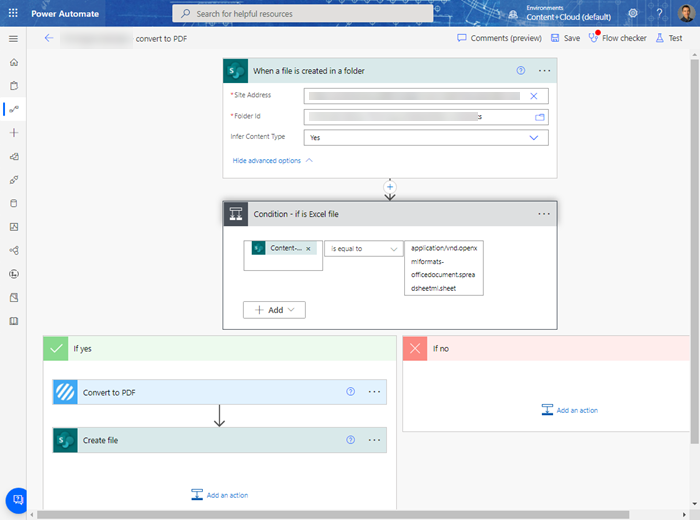
Syntex structured document processing actually doesn't directly support Excel files so a quick conversion to one of the supported formats (JPG, PNG or PDF) is needed - I recommend PDF to avoid the uncertainties of image processing. Power Automate offers a couple of simple ways to convert an Office file to PDF and because you call into Syntex unstructured document processing through a Power Automate Flow you create, this is convenient all round. Some options are:
- Move the file to OneDrive temporarily and use the 'Convert file' action with a target type of 'PDF', then copy or move back
- Use a 3rd party conversation service which has a Power Automate connector. Encodian works great and is free for small volumes
To avoid a recursive loop you should add a check that the file being created is indeed an Excel file before converting. You'll need a check such as:
Content-Type is equal to 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
Your file is now ready for Syntex processing.
2. When working with tables, try structured document processing first
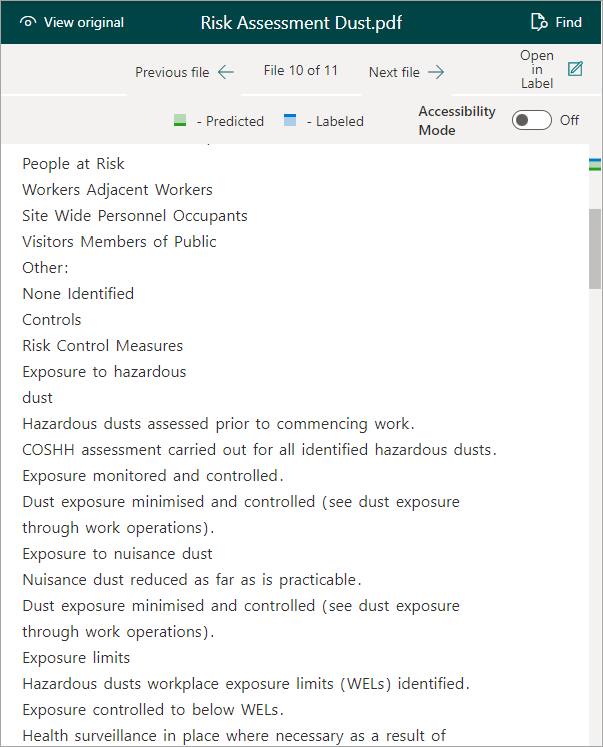
From the two Syntex approaches, document understanding often isn't well-suited to extracting content from tables. The main reason for this is that Syntex document understanding strips away all the structural and formatting elements of the document to leave just the raw content. Consider the following document:
What Syntex actually 'sees' for this document has all of the formatting removed - we see this when labelling documents in the training process:
As a result, extracting contents from a certain row or column in a table can be difficult in document understanding. You might be able to do something with before/after labels and a proximity explanation, but accuracy might vary. In these situations, it's worth trying a switch to structured processing. The model there has special support for processing tables and it's capable of detecting rows and columns in a table - this makes it possible to zone in on 'row 4, column 2' or whatever you need.
Of course, what comes with a change to structured processing is a completely different approach (with its Power Automate integration) and pricing. But, you might need to go this way if the content you're trying to extract is tabular.
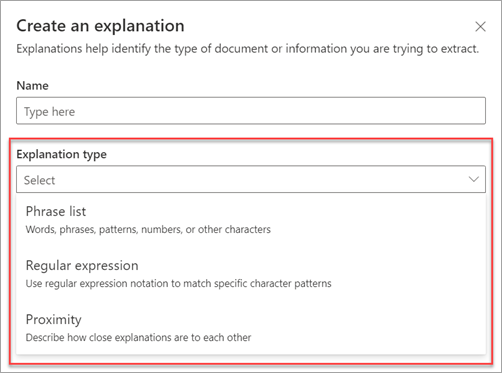
3. Implement a 'proximity explanation' and train on more documents when extracting content in a less describable formats
In Syntex document understanding models, when creating a Syntex extractor to recognise some content in a document and pull it out, it's worth understanding the following - unless specific steps are taken Syntex is best at extracting content in known, describable formats. For example, an extractor you create may be accurate immediately if you're extracting a consistent format such as a postcode or set of product IDs for example. However, training a model to recognise arbitrary data can be more difficult even if it's in a consistent place in the document. This becomes an important aspect of working with Syntex and something to plan for.
Consider two scenarios:
- Extracting a product description (lots of arbitrary phrases)
- Extracting a product ID in form XXX-123456-YY (distinct pattern)
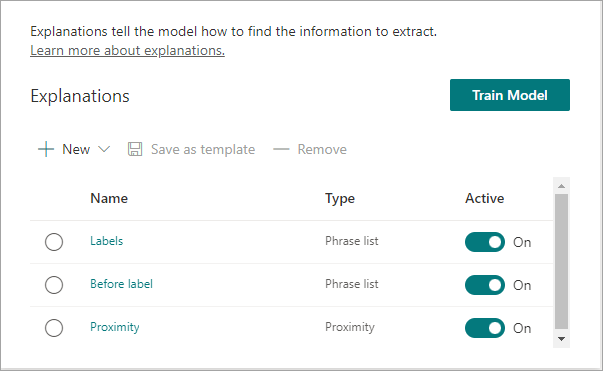
In addition to the AI machine teaching you do when providing Syntex with some sample documents, the 'explanations' you create are vital here:
My tips for extracting more arbitrary formats are:
- Implement a proximity explanation in conjunction with something just before or just after the content you're trying to extract
- Train on larger numbers of documents - don't just stop at five sample docs, provide Syntex with ten or more
- Expect to spend a bit more time on these scenarios
With some tuning, you should be able to get the extractor accuracy to where you need it to be. If not, see tip #2 - setting up a quick test with Syntex unstructured document processing to see if that's more effective is a good idea at this point.
4. Combine Syntex with formatting in SharePoint lists and libraries
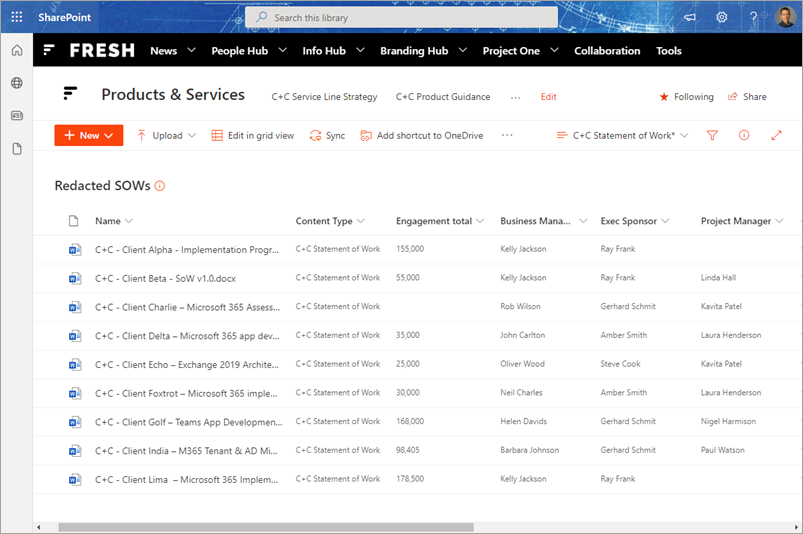
Syntex and SharePoint JSON column formatting are a winning combination - I use them together frequently. Consider the case where you're extracting some content from documents with Syntex, and of course the values are extracted from the document into list item values - when some column formatting is applied we can really bring out the value of what Syntex has found.
From this:
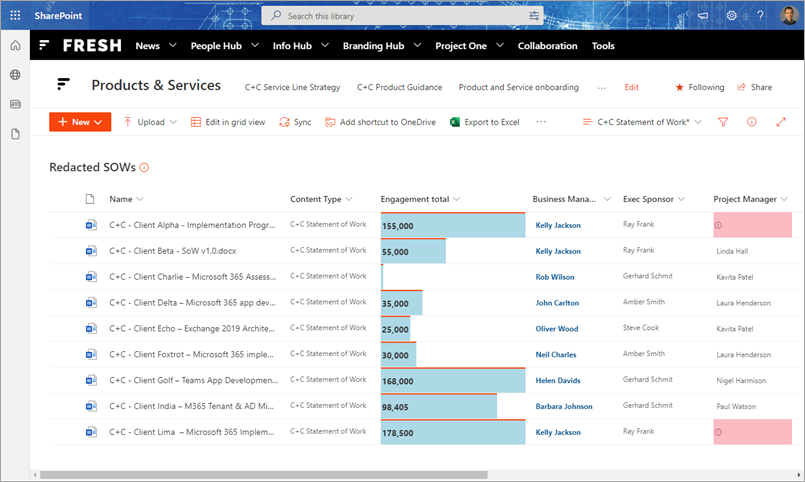
To this:
We can now get an instant view across many documents at once:
-
Engagements with a higher value become obvious from the Excel 'data bar' style formatting on that column
-
The business manager is highlighted in bold, blue text
-
Any missing values from the project manager field are highlighted in red
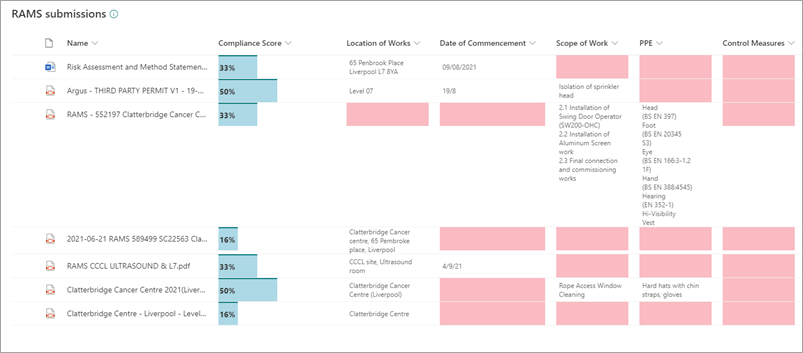
In another example, I use very similar formatting but the emphasis is on highlighting the missing gaps across the documents (as shown by the red):
This provides an intuitive, instant picture of how complete the documents are according to what Syntex found in them. This can be a useful technique when Syntex is used with documents where it's important that certain information is present - which applies to many of the world's is commonly the case when you think about it.
5. Combine Syntex with Power BI reporting to measure document compliance
Expanding on the theme behind the formatting approaches shown above, many business processes rely on documents being completed to a certain standard - the document represents an important form of information exchange or capture. The RAMS review process I discuss above is a great example of this. I'll talk about that particular scenario in more detail in a future article, but as we're discussing general concepts today this idea of "Syntex + reporting" is, I feel, worthy of being a top Syntex tip.
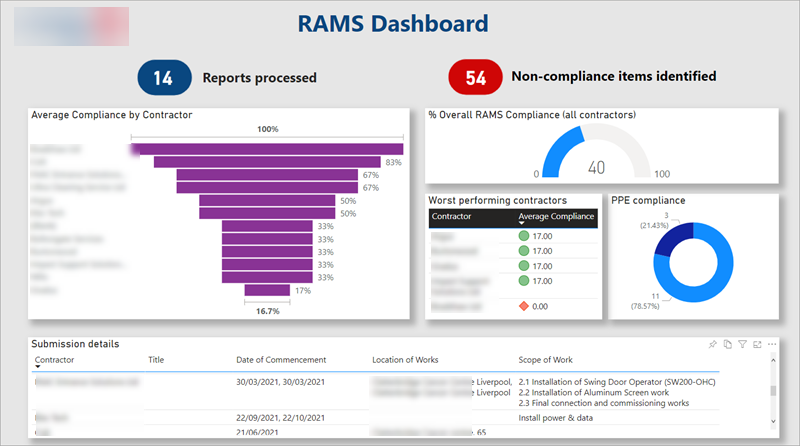
Consider that for any process where information completeness is important, measuring and reporting on this is likely to be valuable. For my client's scenario where fully completed RAMS method statements are a guardrail to help ensure safe working, we implemented a Power BI dashboard to provide insights on to what Syntex was finding. As you can see in the image below, this measures overall 'process compliance' levels, and measures such as the average fidelity of documents from individual subcontractor companies. This allows us to create a subcontractor 'leader board', helping the team understand where there may be greater risk and what to investigate:
This does rely on your Syntex AI models being accurate for the documents you are processing, but even without full accuracy the insights help guide you to where improvements can be made.
Summary
Syntex is an amazing technology and while other AI-based document processing solutions have existed for a while (often vertical-specific, such as legal or contracts management solutions), the advantage Syntex has of being baked into your core collaboration platform is profound and opens many doors. With a good understanding of the constructs and capabilities together with some imagination, Syntex can be the foundation for some high value solutions. Hopefully this post provides some inspiration and useful tips!