In recent articles I've covered SharePoint Syntex from a few angles. Most recently in Automate creation of new documents with SharePoint Syntex Content Assembly we looked at exactly that, automated document creation using the scenario of role description documents, showing the end-to-end process of using Content Assembly. Here at Content+Cloud the scenario is a good fit for Syntex in our business because we have a large number of open roles, which equals a large number of documents, and they're all based on our common template for role descriptions. With Syntex Content Assembly we can simply create an item in a SharePoint list, run the process, and have a Word document created in our C+C branded format which combines the individual specifics for a new role with our standard content on benefits, pension, approach to hybrid work, office locations, and so on.
Having spent some time with Syntex Content Assembly, in this post I want to share some tips which might accelerate your understanding.
Syntex Content Assembly tips
Tip #1 - Understand the 1:1 relationship between your Syntex modern template and where it's created
Syntex Content Assembly is based on creation of a 'modern template', a new construct in Microsoft 365 and SharePoint which acts as the base template for the Word documents you are going to create. One aspect of Content Assembly which needs consideration is that today the template lives in the SharePoint document library you create it in - and nowhere else. There is a 1:1 mapping between your template and this document library:
What this means is that if you'd like to generate documents from this template across your tenant (e.g. different business units) you'll need to recreate the modern template in multiple locations. An alternative approach could be to centralise the creation process into one doc lib and then use Power Automate to 'send' the created document instances to where they need to be. Either way, you need to consider this as a primary consideration when working with Syntex.
Tip #2 - Syntex Content Assembly stores modern templates in the hidden 'Forms' area in the document library
Building on the first tip, it's useful for more technical SharePoint people to understand where modern templates are stored in SharePoint's internals. The answer is they get stored in the hidden 'Forms' directory inside the document library you create the template in. You'll never see this in the SharePoint front-end, but using a tool like the SharePoint Client Browser allows you to see this - specifically a subfolder created within 'Forms' which has the name of your template with spaces removed. In here you'll see the .docx or .pptx file for your template:
Armed with this knowledge, if you have access to SharePoint development skills it's certainly possible to create a single Syntex modern template and use it in multiple locations across your tenant. Use of SharePoint file/folder APIs is the key (perhaps with PnP or a SharePoint migration tool to help), but you could nominate one location as a master and ensure the template is synchronised to other locations. To put this in context, one example could be if your organisation has multiple countries and each should use the same role description template - by synchronising updates to the modern template with each of the locations, you can effectively use one shared template globally.
Tip #3 - keep up with Syntex capability updates: things are changing!
Content Assembly, like the rest of Syntex, is moving fast and it's worth monitoring the Microsoft 365 to see what's coming. As a great example, when I started writing this article (May 2022) one annoying limitation was that you couldn't have Content Assembly drop values into a table within a Word template. This was frustrating because it's common for a document template to have a table (or several) containing different values in each created document - our C+C role description document has core role details such as title, hours, department, reporting line etc. in a table for instance. When using Syntex Content Assembly a few weeks ago, we needed to reformat the document template to remove the tables because Syntex would give messages like this:
But no more!
Another great capability launched in the last few weeks is
the ability to create PDF documents (not just Word) using Syntex Content Assembly - this came in late May/early June. So, stay on top of things by going to the
Microsoft 365 roadmap and filtering on Syntex.
Tip #4 - deal with pre-requisites first: create the SharePoint list/taxonomy and have the document ready
Having been through the process a few times, one recommendation I have with Content Assembly is to ensure you have your prerequisites created and to hand before you go through the 'modern template' creation process. Not doing this is the equivalent of trying to book a holiday without your credit card or passport number to hand - you'll only get so far before realising you need to stop, gather up some things, and most likely abandon the process to restart later.
With Syntex Content Assembly, you map placeholders in your document to the columns in the SharePoint list (or taxonomy terms) where the data will be pulled from - so it makes sense that in the mapping process the source data needs to exist for it to be selected. In the example below these are shown in the right-hand panel by Syntex:
There are actually a couple of variants here - consider that in Syntex Content Assembly, the value to be dropped into a particular placeholder in your document can come from:
- A particular column value in a SharePoint list item (likely to be the most common case)
- A term in a SharePoint taxonomy term set
- A one-off value entered manually by the user
So what we're really saying is that in the first two cases, make sure the SharePoint 'thing' exists first. When using list items for your document creation process, creating the underlying SharePoint list first is important - even if you only create the list and define the columns but don't yet add any data. To put this in context, my SharePoint list for C+C roles looks like the image below - the columns on the right are multi-line fields with lots of detail on the specific role so I've blurred those out, but hopefully the consideration is clear:
In summary, make sure the list and columns (or taxonomy term set) exist before creating the Syntex modern template so that you can map to them.
Tip #5 - avoid SharePoint rich HTML fields with Syntex Content Assembly
There a few 'compatibility' considerations but one in particular I'd like to call out is that SharePoint fields containing HTML (e.g. for rich formatting such as bullet lists, tables, font styles etc.) won't come over to your document well. Your formatting will be lost and you'll see raw HTML in your Word document like this:
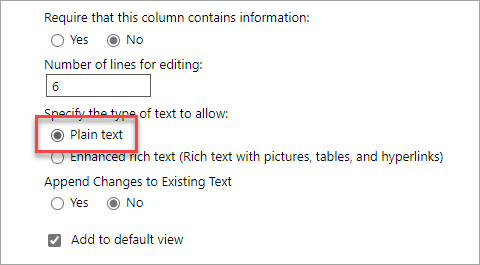
To avoid this, ensure any multi-line SharePoint fields are plain text only:
Other restrictions include:
- Only Word/PDF are supported for now - no PowerPoint or Excel
- Your Word template cannot have comments or Track Changes enabled
- Content controls in Word (remember those?) are not supported
- Images cannot be dropped into the document - only text
In addition to the Microsoft 365 roadmap for high level details, see the 'Current release limitations' section of the
Microsoft documentation on Syntex Content Assembly to keep up with these constraints and new capabilities as Syntex evolves.
Summary
Despite being a relatively new technology Syntex doesn't have too many foibles. Microsoft are putting advanced process automation capabilities into the hands of every (licensed) Microsoft 365 and SharePoint user here, the Content Assembly feature ticks the box of generating new documents as the counterpart to core the Syntex ability of reading, understanding, classifying, and extracting key information from documents. On the document generation side, in addition to the lower-level constraints listed above, it's worth remembering of course that the document creation process still involves a couple of clicks - we still don't have end-to-end automation without human involvement. However, we can be sure that will appear on the roadmap soon most likely through Power Automate integration. Syntex has a bright future as an automation enabler which is relevant to almost every sector and organisation - understanding how to approach Syntex and some of the implications of the model is important to get the most value. Hopefully this post has been useful.